
Cognition laat met FrontierCode iets zien dat n8n-gebruikers snel herkennen: code of workflowlogica kan op het eerste gezicht werken en toch ongeschikt zijn voor productie. De harde vraag is niet of een AI-agent een node, script of API-call aan de praat krijgt. De vraag is of jij die wijziging veilig durft te deployen, debuggen, overdragen en later aanpassen.
FrontierCode is volgens Cognition gebouwd om precies dat verschil te meten. De benchmark beoordeelt niet alleen correcte output, maar ook scope, tests, stijl, regressierisico en de vraag of een maintainer de pull request echt zou mergen. Dat maakt de benchmark relevant voor iedereen die n8n combineert met AI-agents, Code nodes, HTTP Request nodes of custom scripts.
De aanleiding: Cognition introduceert FrontierCode
Cognition kondigde FrontierCode aan als coding eval die de lat hoger legt voor moeilijkheid en codekwaliteit. Volgens Cognition kostte elke taak meer dan 40 uur werk van leidende open-source maintainers. De kernzin uit de aankondiging is scherp: modellen schrijven vaak slordige code die werkt, maar niet onderhoudbaar is. FrontierCode probeert daarom te meten of je de code echt zou mergen.
Dat is geen klein detail voor n8n. In n8n ziet een workflow er vaak overzichtelijk uit omdat de nodes visueel naast elkaar staan. Onder die visuele laag zitten expressions, JSON-transformaties, credentialkeuzes, retrygedrag, rate limits, webhookroutes en soms JavaScript in Code nodes. AI kan zo'n workflow snel uitbreiden. Maar een workflow die één test-run haalt, kan alsnog stuklopen bij een lege array, een verlopen token, een afwijkend API-response of een handmatige herstart.
De recente GSC-context van n8nen.nl laat precies zien waar de site op stuurt: praktische Nederlandse gidsen rond n8n nodes, API-integraties, AI-agents, secrets en workflowveiligheid. De laatste sprint heeft onder meer HTTP Request, Wait node, secrets en AI-agent content aangescherpt. Dit artikel past daarom niet als algemeen AI-nieuwtje, maar als productiecheck voor mensen die AI gebruiken om n8n workflows te bouwen.
Waarom bestaande coding benchmarks tekortschieten voor workflow automation
Veel coding benchmarks meten of een patch een test haalt. Dat heeft waarde. Zonder functionele correctheid ben je nergens. Het probleem begint wanneer teams die score lezen alsof een patch klaar is voor productie. METR liet in maart 2026 zien dat veel SWE-bench-passing PR's bij echte maintainer review alsnog niet zouden worden gemerged. De redenen zijn herkenbaar: kernfunctionaliteit klopt niet, de patch breekt andere code, of de codekwaliteit past niet bij het project.
In n8n zie je dezelfde fout in een andere vorm. Een AI-agent maakt bijvoorbeeld een HTTP Request node met de juiste URL en een testrequest geeft 200 terug. Toch kan de workflow onveilig zijn als de credential hardcoded staat, de error branch ontbreekt, de output shape niet wordt gevalideerd of de workflow geen idempotency heeft. De demo werkt. De productieversie is broos.
Dat onderscheid wordt belangrijker nu mensen AI gebruiken voor meer dan losse snippets. Een agent schrijft niet alleen een expression, maar kiest ook de nodevolgorde, maakt een webhook, voegt een Code node toe, past een prompt aan en koppelt OpenAI, Google Sheets, Slack of een CRM. De fout zit dan zelden in één regel code. De fout zit in scope: de agent verandert te veel, test te weinig of legt niet uit welke aanname hij maakte.
Wat FrontierCode volgens Cognition anders meet
Cognition beschrijft FrontierCode als benchmark voor productiecodekwaliteit. De set bestaat uit 150 taken, opgebouwd met maintainers van 36 open-source repositories. Cognition publiceert drie subsets: Extended met alle 150 taken, Main met de 100 zwaarste taken en Diamond met de 50 zwaarste taken.
De score komt niet alleen uit unit tests. Cognition gebruikt blockercriteria en non-blockers. Een oplossing die een blocker mist, krijgt 0. Blockers kunnen correctness raken, maar ook performance, scope of andere reviewpunten die een maintainer als harde stop ziet. Non-blockers wegen mee als kwaliteitscriteria zoals type safety, stijl en leesbaarheid.
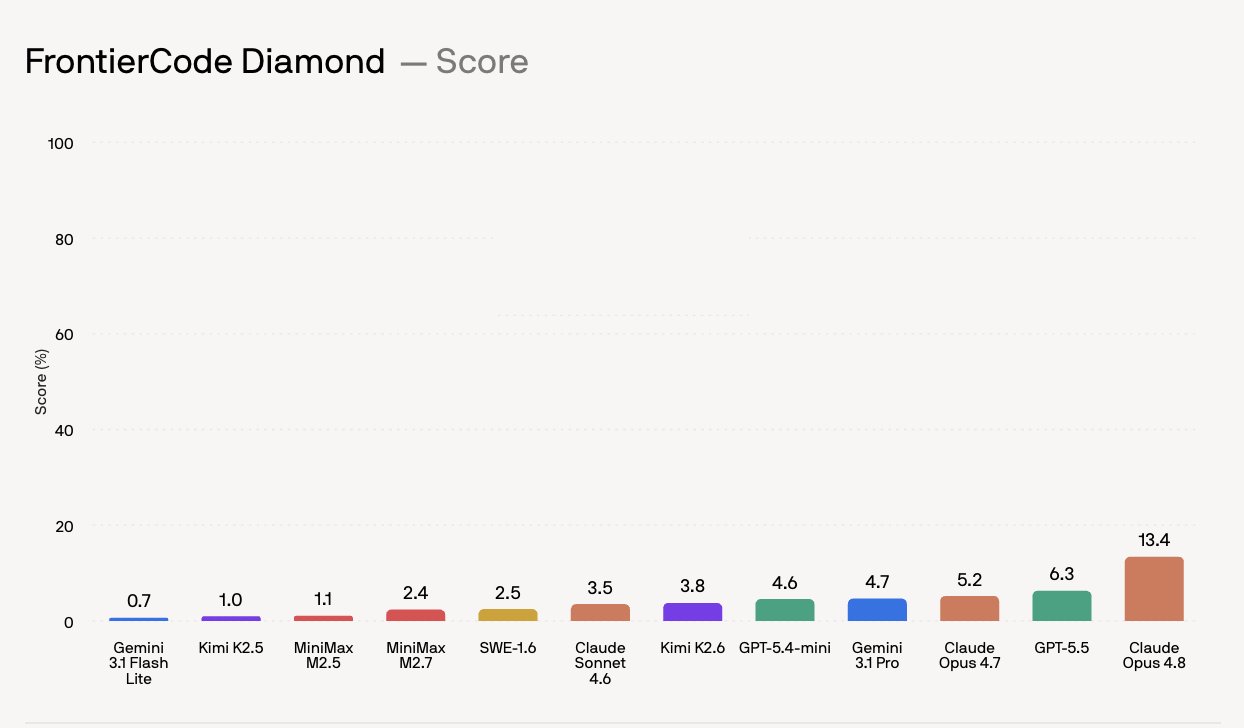
De Diamond-resultaten zijn vooral nuttig als realiteitscheck. Claude Opus 4.8 via Claude Code staat bovenaan met 13,4%. GPT-5.5 via Codex volgt met 6,3%. Claude Opus 4.7 haalt 5,2%. Gemini 3.1 Pro haalt 4,7%. De scores zijn laag omdat FrontierCode niet vraagt: "kan het model iets werkends maken?" De benchmark vraagt: "kan dit door de review van iemand die de codebase kent?"
Voor n8n is dat de juiste vraag. Een workflow moet niet alleen draaien in je eigen test. Een collega moet begrijpen waarom de nodes zo staan. Een klant moet niet omvallen omdat de workflow twee keer dezelfde bestelling verwerkt. Een API-key moet niet in plain text rondzwerven. Een retry moet niet leiden tot dubbele facturen. Dat zijn mergewaardigheidsvragen in automationvorm.
Gebruik FrontierCode als checklist voor AI-gebouwde n8n workflows
Je hoeft FrontierCode niet letterlijk op je n8n workflow te draaien om ervan te leren. De onderliggende rubric kun je vertalen naar een reviewlijst voor workflow automation.
1. Gedrag: lost de workflow het echte probleem op?
Test niet alleen de happy path-run. Test lege input, dubbele input, vertraagde webhooks, ontbrekende velden, rate limits en API-errors. Als een AI-agent alleen de demo-route heeft gebouwd, is de workflow nog niet klaar.
2. Regressie: breekt de wijziging bestaande routes?
Een nieuwe node kan bestaande data shapes veranderen. Een extra Set node kan velden overschrijven. Een promptwijziging kan downstream parsing breken. Bij n8n is regressie vaak onzichtbaar tot een latere node geen veld meer vindt.
3. Scope: heeft de agent alleen aangepast wat nodig was?
AI-agents maken graag extra helpers, extra nodes en extra logging. In n8n leidt dat tot workflows die moeilijk scanbaar worden. Goede automation code is saai: kleine wijziging, duidelijke route, weinig bijvangst.
4. Tests: kun je de wijziging opnieuw bewijzen?
Leg testpayloads vast. Bewaar voorbeeldresponses. Noteer welke credentials nodig zijn, maar nooit de secrets zelf. Maak duidelijk hoe iemand de workflow lokaal of in staging kan herhalen. Zonder testbewijs blijft de workflow een demo.
5. Onderhoud: snapt iemand anders dit over drie maanden?
Gebruik node-namen die uitleggen wat de stap doet. Zet comments bij expressions die businessregels bevatten. Vermijd verborgen logica in Code nodes als een gewone n8n node hetzelfde kan doen. Als code nodig is, hou die kort en plaats de aannames erboven.
Wat we nog niet zeker weten over FrontierCode
Cognition publiceert de taken niet om benchmarkvervuiling te voorkomen. Dat is begrijpelijk, maar het beperkt reproduceerbaarheid. De benchmark gebruikt ook LLM-grading voor sommige kwaliteitscriteria. Dat kan nuttig zijn voor stijl en idiomatische keuzes, maar het blijft een extra beoordelingslaag die teams kritisch moeten lezen.
De ranking combineert model en harness. Claude Opus 4.8 via Claude Code is niet hetzelfde als Claude Opus 4.8 in een willekeurige tool. GPT-5.5 via Codex is niet hetzelfde als een losse chatprompt. Voor n8n maakt dat uit, omdat de omgeving, beschikbare tools en instructies vaak bepalend zijn voor het resultaat.
Ook blijft er leaderboard-risico. Zodra teams scores gaan najagen, optimaliseren ze op de benchmark. Cognition probeert dat te beperken met private tasks, maar elke benchmark wordt na verloop van tijd onderdeel van modelmarketing. Gebruik FrontierCode daarom als signaal, niet als inkoopbesluit.
Praktische implicaties voor n8n-bouwers
Als je AI inzet voor n8n, laat de agent dan niet alleen bouwen. Laat hem ook reviewen tegen productiecriteria. Vraag expliciet om failure modes, testpayloads, rollbackstappen en scopebeperking. Laat de agent uitleggen welke nodes hij bewust niet heeft aangeraakt. Dat laatste zegt vaak meer dan de nieuwe node die hij toevoegt.
Voor workflows met AI-agents kun je starten bij de bestaande gids over n8n AI Agents. Voor visuele agentbouw past de gids over OpenAI Agent Builder. En voordat je AI code credentials laat beheren, lees de uitleg over n8n variables en secrets.
Mijn oordeel: FrontierCode raakt precies de zwakke plek van AI-automation. De meeste teams testen of de output er goed uitziet. Ze testen te weinig of de workflow bij storing, overdracht en onderhoud overeind blijft. Voor n8n is dat verschil duur. Een workflow faalt meestal niet op de dag dat je hem demonstreert, maar op de dag dat een API-response verandert en niemand meer weet waarom die Code node zo geschreven is.
De beste n8n-workflow die AI voor je bouwt, is daarom niet de snelste demo. Het is de workflow die een andere bouwer kan openen, nalopen, testen en zonder stress aanpassen.